
URL адрес страницы сайта: Что это такое и где его взять?
Многие слышали о понятии URL адреса, но немногие знают, зачем он нужен и что собой представляет.
Поэтому было бы полезно разобрать несколько вопросов, связанных с темой «URL адрес» – что это такое, где используется, какова структура и другие интересные моменты.

Содержание:
На самом деле, если вы хоть раз в жизни заходили в интернет, значит, пользовались URL адресом. Все намного проще, чем может казаться на первый взгляд.
Общая информация
URL адрес – это адрес какого-либо ресурса в интернете.
Под понятием «ресурс» в прошлом предложении имеется в виду сайт, изображение, документ или что-либо еще, что только может находиться в интернете на каком-то удаленном сервере.
Теперь вернемся к URL адресам. Собственно, этот адрес показывает, где можно найти тот или иной ресурс.
К примеру, если это URL какой-то страницы в интернете, чтобы ее отобразить, нужно найти ее исходный файл, то есть код.
URL адрес и показывает, в каком «шкафу» находится «рубашка» в виде сайта.
Точно также с URL изображения или документы – эти файлы должны где-то находиться, а точнее, на сервере. URL показывает адрес этого сервера.
Он имеет свою уникальную структуру, о которой речь пойдет далее.
Пока что можно сказать, что URL расшифровывается как Universal Resource Locator, то есть универсальный указатель ресурса. А если по-русски, то это адрес сервера, на котором находится ресурс.
Кстати, путь от конечного сервера к компьютеру можно представить в виде самой обычной иерархии, показанной на рисунке №1.
Как видим, вверху стоит тот самый сервер, на котором находится нужный нам ресурс, а внизу – компьютер, то есть пользователь.
Между ними есть вспомогательные серверы.
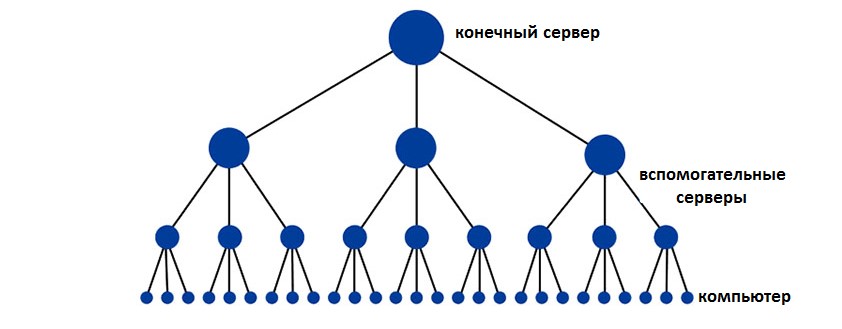
№1. Иерархия доступа к серверу
Структура
Итак, структура URL адреса для хранения станицы, изображения, документа и других файлов выглядит следующим образом:
- <способ>://<логин>:<пароль>@<хост>:<порт>/< путь>?<параметры>
Теперь разберем каждую из этих составляющих по отдельности:
- <способ> — представляет собой способ доступа к ресурсу, многим разработчикам будет понятнее, если сказать, что это сетевой протокол;
- <логин>:<пароль> — это соответствующие параметры доступа к ресурсу;
- <хост> — это имя хоста в системе DNS, также может записываться как IP-адрес хоста;
- <порт> — данный параметр относится к хосту;
- <путь> — содержит в себе информацию о доступе к ресурсу, определяется сетевым протоколом, о котором речь пойдет дальше;
- <параметры> — отдельные параметры страницы, которые отвечают за файлы внутри указанного ресурса.
Также некоторые добавляют в конец вышеприведенной структуры такой параметр, как #<якорь>.
Но многие специалисты считают его избыточным и ненужным.
Данный параметр также указывает на ресурс внутри основного ресурса, но того же результата можно добиться путем правильного использования пункта <параметры>, как это, собственно, и происходит в современном мире.
Основным параметром в вышеприведенной схеме является <способ> или просто сетевой протокол. Самым известным из них является http.
Если сказать просто, сетевой протокол представляет собой набор неких инструкций по доступу к данным.
Хотя в учебниках можно найти информацию о том, что это «соглашения интерфейса логического уровня, определяющие способ обмена между программами», на самом деле все намного проще и сводится к тому, что сказано выше.
К примеру, тот же http передает данные в виде гиперссылок.
Существует огромное-множество таких вот сетевых протоколов. К примеру, ftp предназначен для того, чтобы передавать данные по сетям типа TCP.
Есть также https – это тот же http, но с дополнительным уровнем защиты. Такой сетевой протокол, как opera использует специальные инструкции и страницы браузера Opera.
Существует также chrome, который действует подобным образом. Все же чаще всего мы, обычные пользователи, используем самый обычный http.
Разработчики пользуются ftp и подобными ему специализированными протоколами.
Теперь перейдем непосредственно к примеру. Возьмем одну из статей на этом сайте и ссылку на нее – https://geek-nose.com/kak-v-vk-zakrepit-zapis-na-stene/ (кстати, очень неплохая статья).
Так вот, как видим, здесь все соответствует описанное выше структуре.
Параметр <способ> здесь http, после него идет стандартная конструкция «://». Затем идет параметр <хост>, в данном случае это geek-nose.com.
Все, что касается хоста – логин и пароль – обычному пользователю не видно. И после «/» идет непосредственно адрес нужной статьи, это уже параметр <путь>.
Никаких дополнительных параметров здесь нет.
Вот так, собственно, и выглядит любой URL адрес в мире.
к содержанию ↑Как узнать URL
Интересно, что многие не знают, где взять этот самый URL адрес. Конечно, если речь идет о сайте, то его можно посмотреть в адресной строке.
Для примера возьмем ту же описанную выше статью.
На рисунке №2 показано расположение ее адреса в браузере.
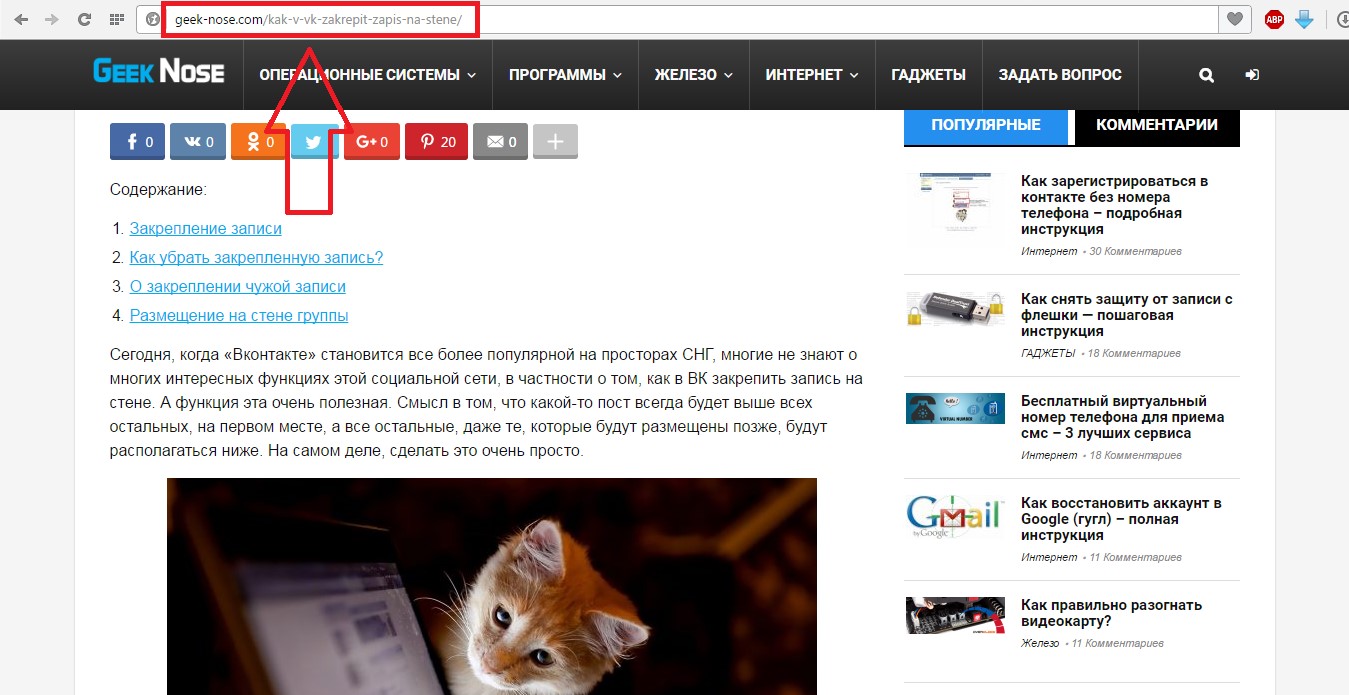
№2. Расположение URL адреса в браузере
Стоит отметить, что в браузере обычно не указывается параметр <способ> из вышеуказанной структуры.
Как видим, и на рисунке №2 рядом с началом адреса нет надписи «http». Это вполне нормально. Обычно данный параметр становится видным уже после копирования данного адреса в буфер.
Кстати, копирование здесь происходит вполне стандартным способом – нажатием сочетания клавиш +.
Второй способ заключается в том, чтобы выделить соответствующий текст, нажать на него правой кнопкой мыши и в выпадающем меню выбрать пункт «Копировать», как это показано на рисунке №3.
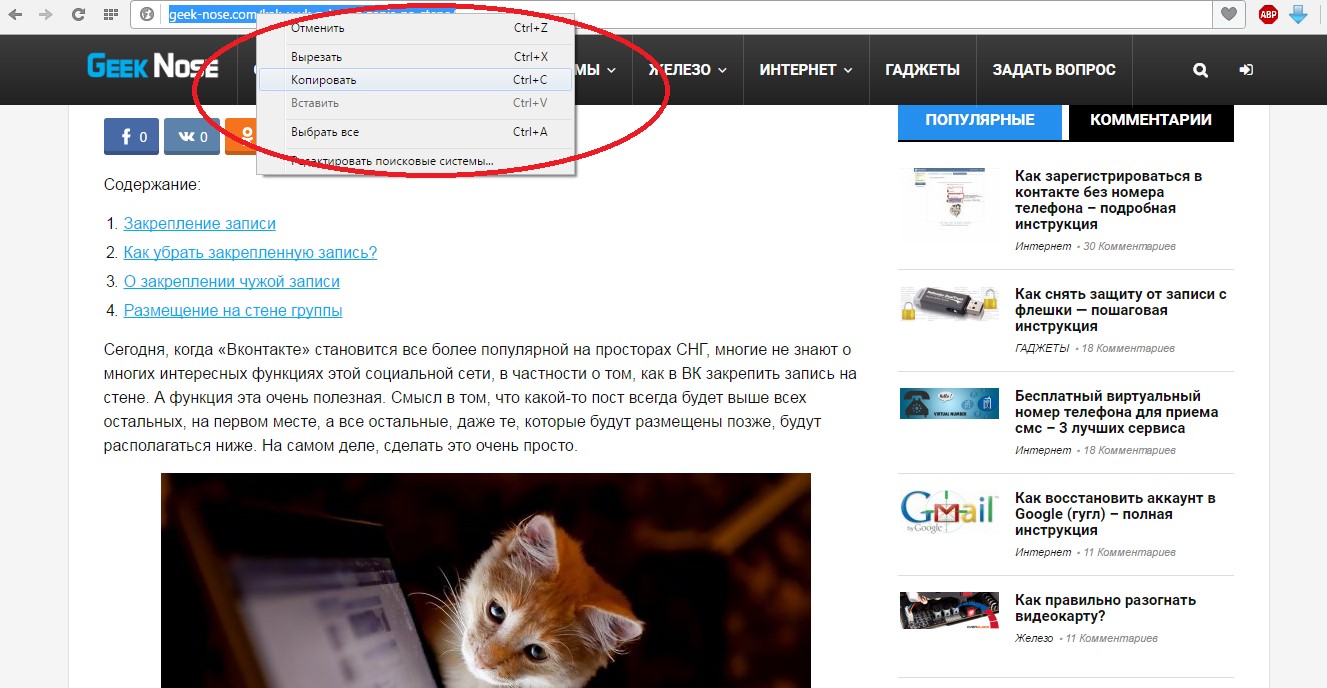
№3. Выпадающее меню при выделении адреса сайта
Но, как мы говорили выше, URL адрес есть не только у целых сайтов, а и у отдельных файлов, таких как изображения и документы.
Чтобы узнать их URL, тоже можно нажать на соответствующий файл, к примеру, картинку, правой кнопкой мыши и в меню выбрать пункт «Копировать адрес изображения», как это показано на рисунке №4.
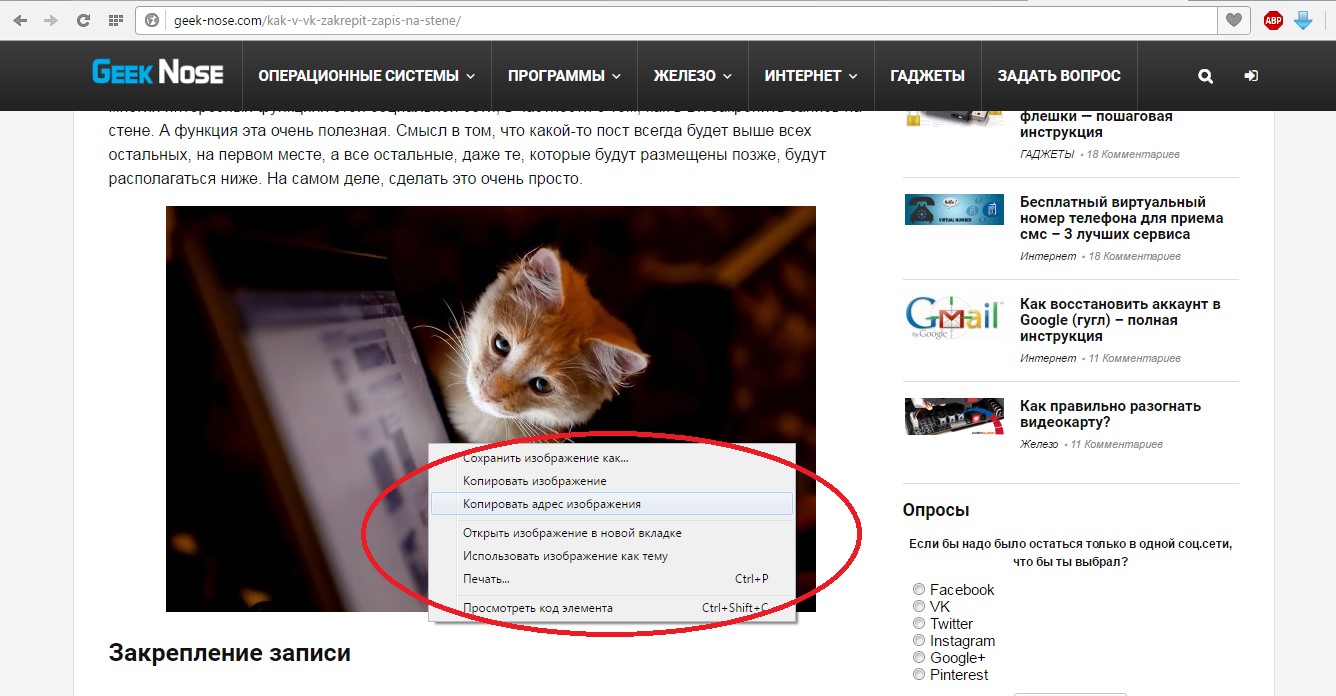
№4. Выпадающее меню при нажатии на изображение правой кнопкой мыши
Если речь все-таки идет о документе, на него тоже всегда можно кликнуть правой кнопкой мыши, после чего увидеть выпадающее меню и в нем выбрать пункт «Копировать адрес ссылки», как это показано на рисунке №5.
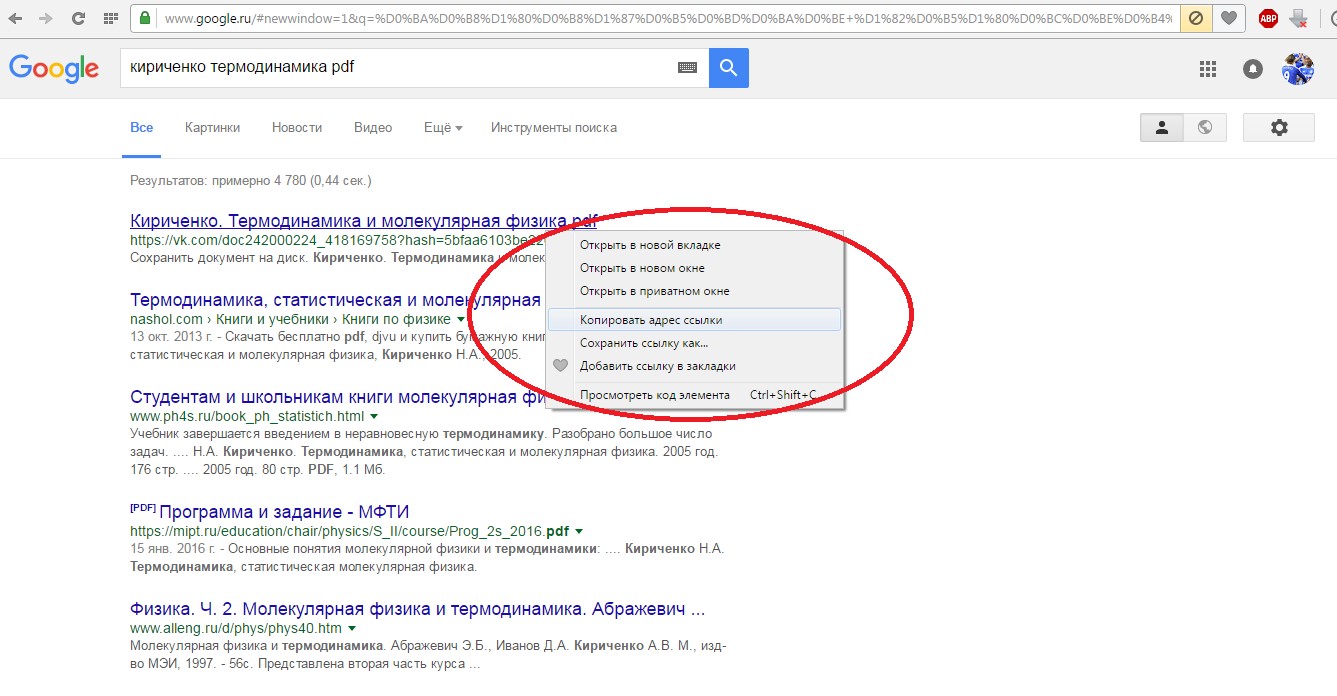
№5. Выпадающее меню при нажатии правой кнопкой мыши на документ
После того, как соответствующая ссылка была скопирована, то есть, помещена в буфер обмена, ее можно вставить в ту же адресную строку или же в текстовый документ.
Собственно, это и есть способ, как узнать адрес того или иного ресурса.
К примеру, адрес скопированного выше изображения выглядит вот так: https://geek-nose.com/wp-content/uploads/2016/03/kak-v-vk-zakrepit-zapis-na-stene-%E2%84%9611-650×406.jpg.
Как видим, в конце находится расширение файла – .jpg. После параметра <хост> здесь после «/» идет многоуровневый адрес доступа к фотографии.
Такой адрес означает, что картинка с названием «kak-v-vk-zakrepit-zapis-na-stene-%E2%84%9611-650×406.jpg» находится на хосте geek-nose.com в папке под названием «wp-content», внутри которой находится папка «uploads», внутри неё «2016», а в ней еще и папка «03».
В принципе, в данном адресе все предельно ясно. Вопросы вызывает лишь вот эта конструкция: «%E2%84%9611». Это зашифрованный фрагмент адреса.
к содержанию ↑Шифрование в URL
Итак, где взять этот адрес сайта или иного ресурса, мы уже разобрались. Но иногда при копировании, к примеру, вот такого: «https://ru.wikipedia.org/wiki/Смартфон» копируется что-то вот такое:
- «https://ru.wikipedia.org/wiki/%D0%A1%D0%BC%D0%B0%D1%80%D1%82%D1%84%D0%BE%D0%BD» — это самое обычное шифрование.
Не углубляясь в недра познания мира сего, скажем, что все URL адреса записываются только с помощью определенного набора символов.
И кириллица в него, как мы понимаем, не входит. Поэтому, чтобы машина могла понять, куда ей следует обращаться, происходит шифрование.

Делается это в два этапа:
- Кодирование в Юникод, на выходе – последовательность из двух байтов.
- Кодирование в шестнадцатеричный код.
В более современных браузерах имеет место сначала кодирование в Base58.
Каждый байт разделяется знаком процента, то есть «%». Собственно, этим и обуславливается то, что мы можем видеть выше.
Современные браузеры уже не дают пользователю видеть ссылки с шестнадцатеричными цифрами.
Поэтому если вы копируете ссылку в нормальном виде, а получаете что-то вроде «https://ru.wikipedia.org/wiki/%D0%A1%D0%BC%D0%B0%D1%80%D1%82%D1%84%D0%BE%D0%BD», просто обновите свой браузер!
к содержанию ↑История
История создания URL адресов довольно интересная.
А затронем мы эту область для того, чтобы лучше понимать, что собой представляют данные конструкции и зачем были созданы.
Хотя, из вышесказанного уже можно понять, что URL представляет собой адрес ресурса в интернете, а создан он был для того, чтобы этот ресурс банально можно было в нем найти.
Но интересно, что впервые про URL заговорили в Женеве. А изобретателем его считается Тим Бернерс-Ли.
Случилось сие событие в 1990 году – намного позже, чем могло бы показаться на первый взгляд.
Сначала URL использовали для того, чтобы обозначать расположение отдельных файлов в интернете, но потом специалисты поняли, что это очень удобно и стали применять его для обозначения практически всех возможных ресурсов интернета.
Постепенно на смену URL пришел так называемый URI. Согласно учебнику по сетям, эта конструкция тоже представляет собой символьное определение ресурса.
В URL входит, во-первых, имя сайта, а во-вторых, его расположение.
Существует также URN – это или только адрес сайта/ресурса, или его имя. URI же объединяет в себе URL и URN.
Изобретена была такая конструкция в том же 1990 году, что и ее прародитель, URL.
Хотя завершение работы над ней датируется аж 1994 годом. В 1998 году вышла новая версия URI.
В 2002 году было сообщено о том, что термин URL устарел и лучше использовать вместо него только URI.
Таким образом, самые использованные способы обозначения расположения файлов в интернете берут свое начало в Женеве, а конкретно в Европейском совете по ядерным исследованиям или просто CERN.
Последнее более известно тем, кто хоть иногда смотрит новости.
к содержанию ↑Перспективы
У современного URL есть огромное количество недостатков, среди них:
- Малая гибкость;
- Проблемы с шифрованием;
- Указание пути на несуществующие ресурсы;
- Навязывание ресурсам иерархической структуры (об этом говорил сам создатель URL);
- Плохая работа с гипертекстовой структурой.
По этим и другим причинам была предложена совершенно новая интерпретация URL под названием PURL.
В рамках данного стандарта будет использоваться несколько иной подход.
Все будет основано на существовании базы данных PURL, в которой и будут храниться все имена и пути к ресурсам.
Система будет регулярно проверять эти ресурсы и, при необходимости, удалять или обновлять ссылки на них. Таким образом удастся решить три из пяти вышеперечисленных проблем.
Что касается остальных, специалисты пока что находятся на стадии разработки их решений.
Ниже можно видеть весьма интересный и занятный ролик про интернет в принципе.
Его просмотр позволит еще в большей степени понять, что вообще такое URL, и какое место эта конструкция занимает в работе Всемирной паутины.
История Интернета
URL адрес страницы сайта: Что это такое и где его взять?






I viewed your post while looking for some connected data on a blog search... It's a decent post..keep posting and updating the data. https://phrazle.co
Спасибо за прекрасную статью. Очень доходчиво даже для таких темных как я . Спасибо!!!
всё разжёванно до нельзя.спасибо.даже не стал смотреть ролик и так всё понятно
Добрый день. У меня сайт http://cocktailes.ru. Стала регистрировать его в Google, а он требует написание названия сайта через www. Это как?